Many people are familiar with the concept of Time Travel. Time Travel is a great storytelling trope, and is used for movies like "Back to the Future," books like "The Time Machine," and television shows like "Doctor Who." One common theme between all various retellings of time travel is that it is fraught with danger. In "Back to the Future" Marty has to be careful not to alter the past lest he disappear. The Terminator franchise sends robots back in time to make sure the robots do not rise to power. In the end, the warning is the same - altering the past can have grave consequences.
git is a time machine. It allows you to travel up and down the history of your project. Each commit is a blip on that timeline. A commit is a valuable, recorded piece of history.
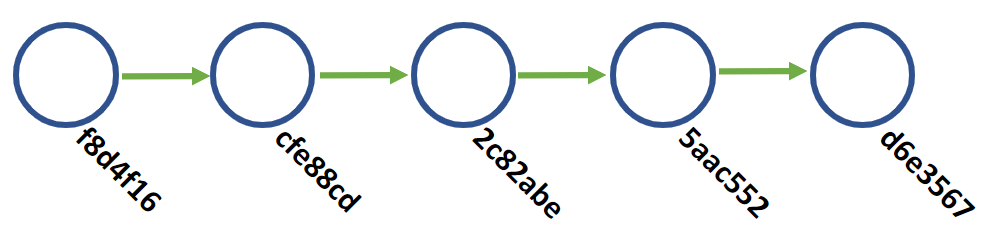
git can allow you to do a great many things as a time traveler. One of the simplest is to just go back in history and observe. git checkout <hash> will move the view of your timeline back to the specific hash, but it does not destroy any work anyone has done. You can always git checkout HEAD to go back to the end of the timeline, or "now." In a way, this is a safe version of time travel. You cannot really mess anything up jumping around commits like this.
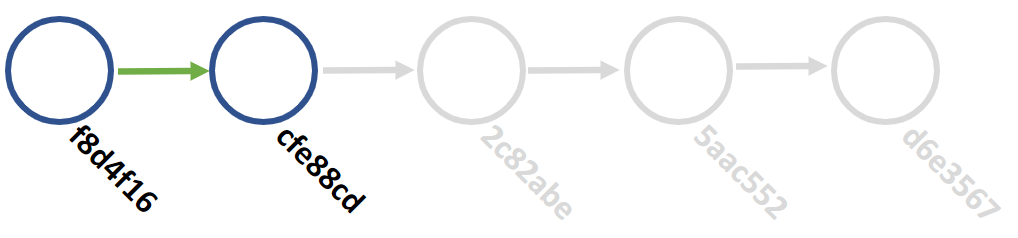
When you go back in time, git lets you know that anything you do in this checked-out state is ephemeral. If you want to make a change, git tells you to create a new branch. A branch is just a parallel timeline. Branches do not interact with the main timeline until you are ready to "merge" the parallel timeline. You can create, alter, and destroy branches as much as you want without affecting the main timeline.
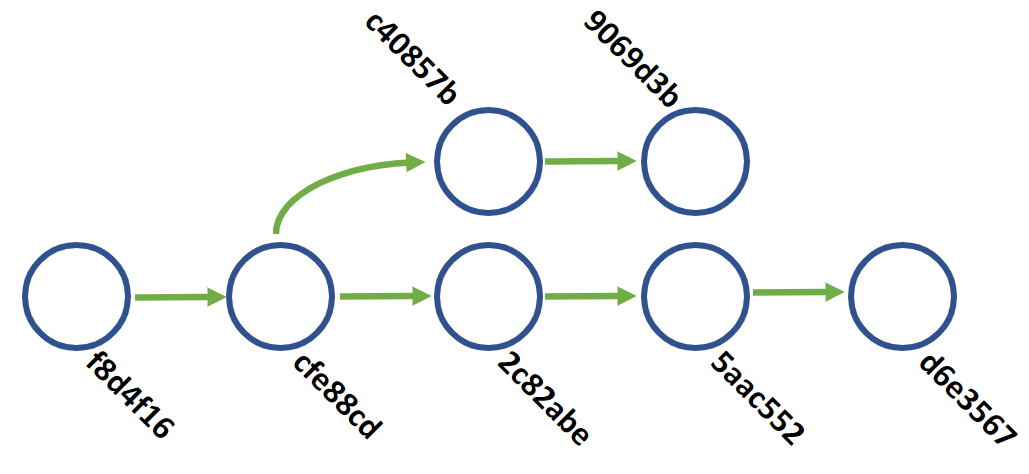
When you are ready to merge a branch, the contents of the branch are added to the timeline as if it was there the whole time. git does some reconciliation to bring the branch into the main timeline (this is what the "merge" commits are in the history), and that alternate timeline/branch is now a part of the main timeline's history.
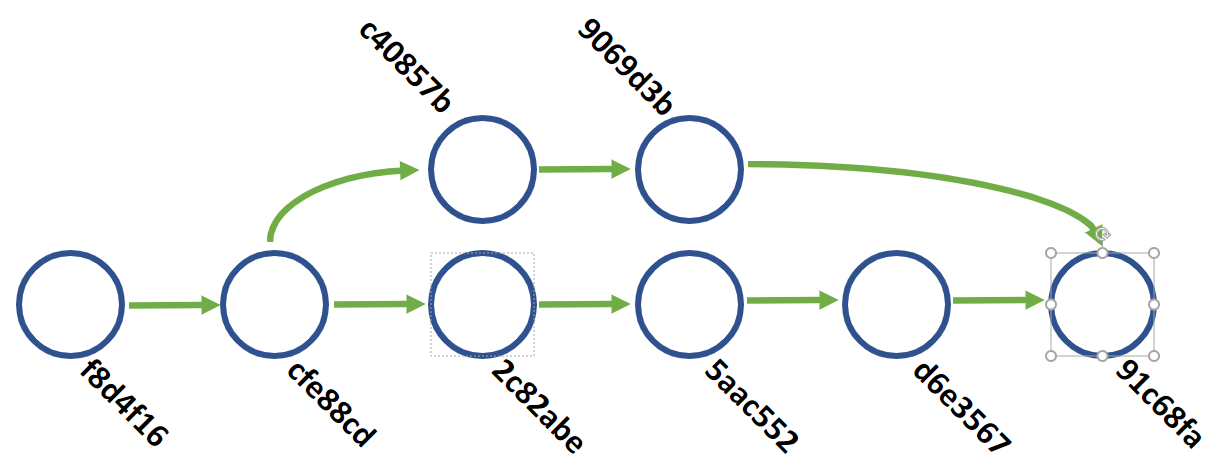
None of this alters existing history, it just appends to it. This is why (generally) branching, committing, and merging are safe workflows.
Rewriting History
This is great and all, but what happens when you need to actually change history, not just append to it. That's where git rebase comes into play. git rebase is a way to rewrite history. That power is as wonderous and scary as it sounds.
There are three times that I find git rebase is useful daily. The first is a branch sync, where I'm working on a remote branch and want to make sure everything is synced up. The second is hiding inconsequential commits from my local history before I push a branch up. The third is because a branch's parent has updated drastically, and I want the new code in my branch. Each of these instances requires me to rewrite what my local history looks like, so we need git rebase.
Why do we go through with all of this? The simplest reason for me is having a clean commit history. Rebasing allows us to make sure that a timeline looks clean with branches coming out and back in, and that the commits that exist matter. Anyone who comes along to work on the code should be able to quickly pinpoint various changes and lifecycles from the timeline. Rebasing allows us to keep a cleaner timeline through the ability to manipulate it.
Rebasing encompasses a list of different things under the hood, so let's look at the actual usages I find common and what is going on.
Branch Syncing
A command I use daily is git pull --rebase origin <branch> to pull remote changes into a local copy of a branch, especially the main branch of a project. While git pull by itself will bring down the changes, it does so by bringing down the changes and stuffing it around any local changes I have made but have not published. This is not a huge problem, but it can become a larger issue when conflicts occur.
Let's say our main branch histories look like this, and my local branch has an extra merge I did locally because of a bug fix:
// Remote
244426b0 2 hours ago - Merged branch feature/time-feature
a7ec8a44 3 days ago - Added Time class
a9cad80d 1 month ago - Deleted unneeded dependency on Vendor\Baz
21420248 1 month ago - Initial Commit
// Local
e454fa2e 10 hours ago - Merged branch bugfix/broken-dependencies
c23d5765 10 hours ago - Updated dependencies
a9cad80d 1 month ago - Deleted unneeded dependency on Vendor\Baz
21420248 1 month ago - Initial Commit
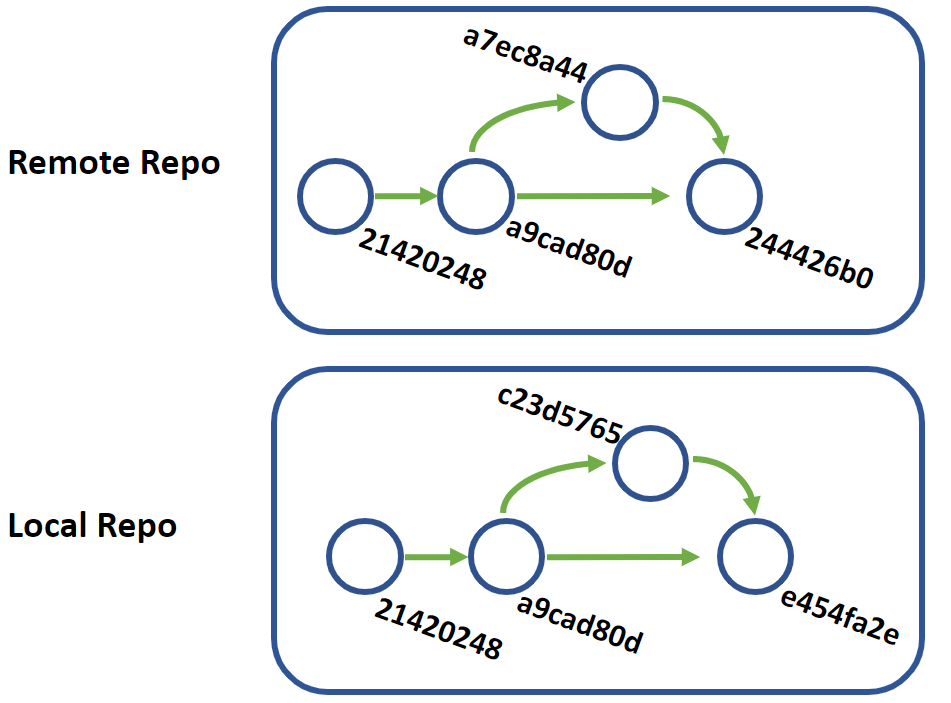
git pull will bring down the two missing commits, but the order will not be as clean as it will order the timeline based on commit time, not necessarily the order in which things were added to the timeline.
244426b0 2 hours ago - Merged branch feature/time-feature
e454fa2e 10 hours ago - Merged branch bugfix/broken-dependencies
c23d5765 10 hours ago - Updated dependencies
a7ec8a44 3 days ago - Added Time class
a9cad80d 1 month ago - Deleted unneeded dependency on Vendor\Baz
21420248 1 month ago - Initial Commit
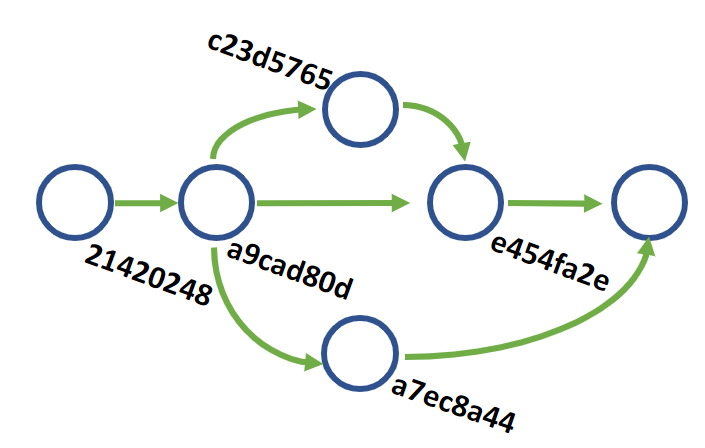
This is not the worst thing in the world, but since I have not pushed my local commit I would prefer it not get mixed in with the existing timeline. git pull --rebase goes a step further and moves any local commits to the end of the timeline, after any remote commits. Our history ends up looking like this:
e454fa2e 1 minute ago - Merged branch bugfix/broken-dependencies
c23d5765 1 minute ago - Updated dependencies
244426b0 2 hours ago - Merged branch feature/time-feature
a7ec8a44 3 days ago - Added Time class
a9cad80d 1 month ago - Deleted unneeded dependency on Vendor\Baz
21420248 1 month ago - Initial Commit
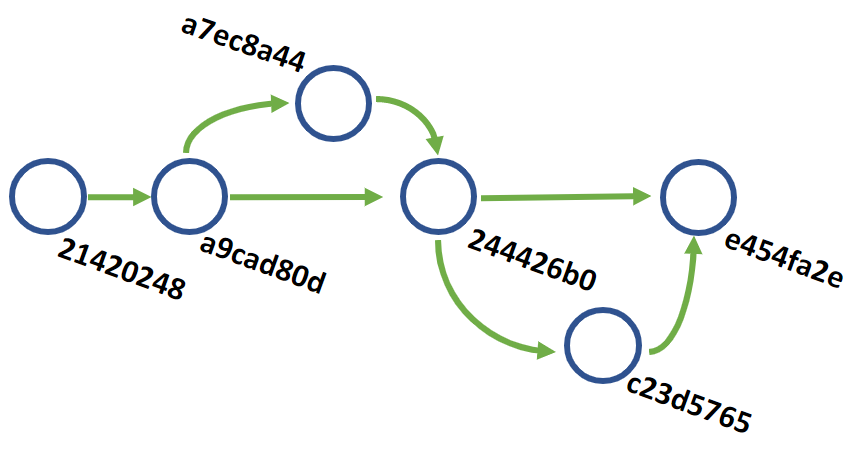
It is a small change, but now our local work is moved and timestamped as after the other work. To me, this is a cleaner history and better group work being done together.
When is this safe?
This is generally safe on most branches. git will only rebase and move your local commits if they do not exist in the remote repository. You may still run into conflicts if you edit the same file as someone else, but the rebase will stop and you get a chance to fix things. Overall this works best when you keep this branch up-to-date as much as possible and are pushing your commits as much as possible. In the worst cases, you can git rebase --abort to stop the pull and rollback and do a traditional pull.
Hiding Unneeded Commits
The other daily rebase I do is when it comes to hiding commits that no one cares about. Have you ever seen a commit log like this?
$ git log --pretty=format:"%h %cr - %s"
b2b99fb 25 seconds ago - Updated dependencies
244426b 4 months ago - Added The Contracts of Open Source
a7ec8a4 1 year, 7 months ago - Fixed comments maybe
a9cad80 1 year, 7 months ago - Typos and fixes
2142024 1 year, 7 months ago - Added some responsiveness
1ba90ea 1 year, 7 months ago - Added false promise post
c23d576 1 year, 10 months ago - Fixed some more grammar issues
e454fa2 1 year, 10 months ago - Fixed typo
e1fd605 1 year, 11 months ago - Upgraded to sculpin 3
be8b7ec 2 years, 1 month ago - Overhaul of the talks and updated a ton of data
9f670ee 3 years, 1 month ago - Update .gitignore
00980fd 3 years, 5 months ago - Clarified a sentence
3ddd2f1 3 years, 5 months ago - Fixed typos
2df0ba3 3 years, 5 months ago - Added cron expression post
Commits in git should be atomic. Atomic commits are commits that do a single thing, but that single thing is a unit of work. In the case above, adding the "false promise" post is actually four total commits - 1ba90ea, 2142024, a9cad80, and a7ec8a4. The last three commits are fixing issues in the post, but the entire unit of work is comprised of those four commits. I should rewrite them as a single commit.
An interactive git rebase is the perfect tool for this job. In this case, we will tell git we want to rebase everything after a certain point, and by making it interactive git will let us manipulate history to clean it up. The first thing we'll want to do is figure out when we want to start to rewrite history. In our case, the new blog post was originally added in 1ba90ea, so we will want to go one step earlier to c23d576. This is the first hangup many people run into. The hash you specify is not included in the list to manipulate.
Now we just tell git to remove the locks and let us work:
git rebase -i c23d576
git will open a text editor and place all of the commits after (but not including) c23d576 into a nice little list for us. We are going back a bit in time so we are dragging in changes after the post, which is another potentially confusing area. What are we looking at?
pick 1ba90ea Added false promise article
pick 2142024 Added some responsiveness
pick a9cad80 Typos and fixes
pick a7ec8a4 Fixed comments maybe
pick 244426b Added The Contracts of Open Source
pick b2b99fb Updated dependencies
# Rebase c23d576..b2b99fb onto a7ec8a4 (6 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup <commit> = like "squash", but discard this commit's log message
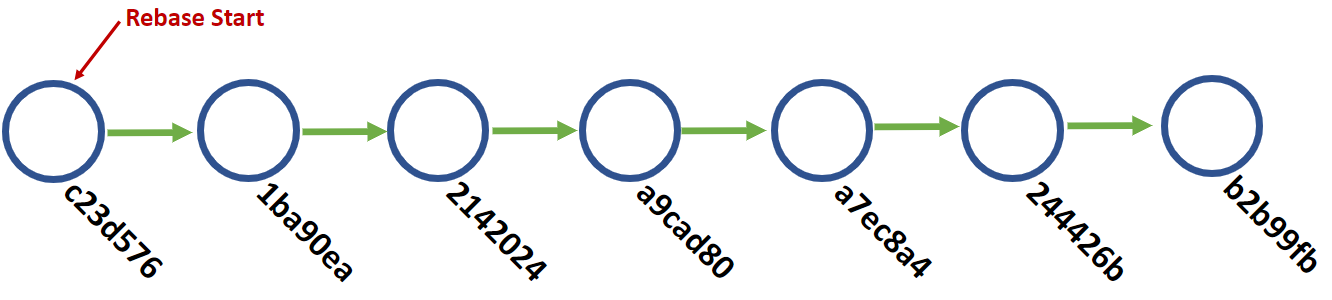
The first four lines are the commits we can manipulate. The first word is a command, which the commented area at the bottom will detail. I have listed the most common five things you can do. The second column is the commit hash, and the rest of the line is the commit message. This screen allows us to queue up what we want to do and will execute it when we save and close this file.
What commands do we normally use?
pickup- Just use the commit as isreword- Use the commit, but change the commit messageedit- Use the commit, but stop and allow us to amend it with further changessquash- Use the commit, but merge it and the commit message with the previous commitfixup- Likesquash, but ignore the commit message
What we want to do is create a single unit of work for adding the post, but we do not want to lose the last three commits. We have two options - squash or fixup. Since history does not care that I made typos or fixed some issues with responsiveness, we will go with "fixup". We will edit the lines to look like this:
pick 1ba90ea Added false promise article
fixup 2142024 Added some responsiveness
fixup a9cad80 Typos and fixes
fixup a7ec8a4 Fixed comments maybe
pick 244426b Added The Contracts of Open Source
pick b2b99fb Updated dependencies
We can then save the file and exit the text editor (^X in nano, :wq in vim). git will then start to do the commands we told it to.
- "pick"
1ba90eaand use it as-is - "fixup"
1ba90eaby adding the changes from2142024 - "fixup"
1ba90eaby adding the changes froma9cad80 - "fixup"
1ba90eaby adding the changes froma7ec8a4 - "pick"
244426band use it as-is - "pick"
b2b99fband use it as-is
If we look at the log now we will see that those other commits have disappeared, but if we look at the files all those changes are still intact:
$ git log --pretty=format:"%h %cr - %s"
ed4d525 64 seconds ago - Updated dependencies
231fe64 64 seconds ago - Added The Contracts of Open Source
8eda557 64 seconds ago - Added false promise article
c23d576 1 year, 10 months ago - Fixed some more grammar issues
e454fa2 1 year, 10 months ago - Fixed typo
e1fd605 1 year, 11 months ago - Upgraded to sculpin 3
We rewrote history to get rid of my typos! Now no one will need to know that I am a poor speller (no comments on this post about spelling mistakes. That's what Twitter DMs are for).
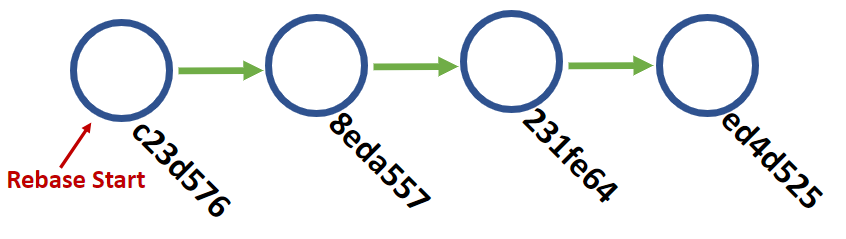
What happened? git rolled back our repository to c23d576 - we went back in time and undid everything after that point. git, however, remembers all the commits after that, so began to rebuild history at that point using our instructions. git began layering on those old commits, but this was new work so we get new hashes. The three "fixup" commits are effectively wiped from history as the pointers shift to make it look like c23d576 went directly to a7ec8a4. A new commit is generated, 8eda557, to symbolize that new history. The last two commits are layered in the same way, with new hashes to symbolize their new place in the timeline.
A side effect of this is the timestamps now all show our fixed-up commit, as well as everything after it, looks like they were done "now" (or 64 seconds ago as I live test all of this). That is because those changes were rewritten 64 seconds ago. We altered history, so git accurately reflects that. It will not lie, and it is not a lie to say we changed 231fe64 and ed4d525 64 seconds ago - they were part of the rebase.
In the end, we are left with a single, atomic commit for a post. This provides a cleaner history and a much more useful history. We can see when the post was committed, but we hide those fixes because ultimately all history needs to worry about is that the post was added.
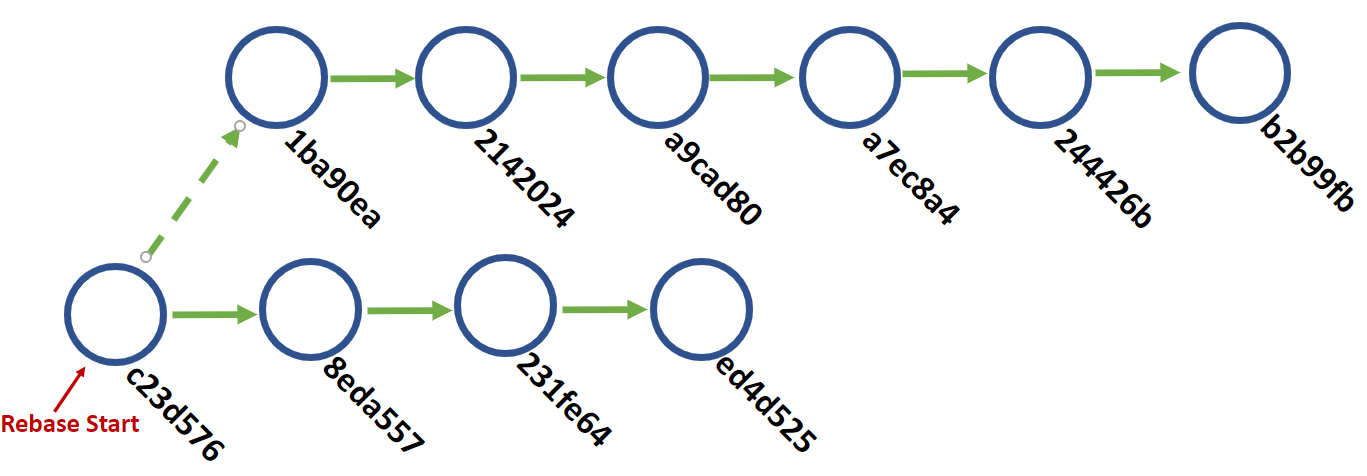
What happened to those original commits? They still exist, but we no longer look at them in the timeline. Technically the timeline actually looks more like this, with those original commits almost like a branch from our rebase start. You could actually checkout b2b99fb and trace its history back to the original rebase commit as it exists in something called the "reflog", which is the full commit history of the repository. For all intents and purposes, it is no longer part of the timeline we are on.
When is this safe?
This type of rebasing is only safe 100% of the time in two instances. The first is on code YOU HAVE NOT PUSHED. I routinely make small commits working toward a goal or fixing bugs I introduce in code. Having those commits are great ways to roll back if things go off the rails. When you are happy with your code, rebase and fixup/squash all those down. This is easy to deal with as it does not deal with force pushing.
The other time this type of rebasing is safe is when YOU are the only one to be working on a branch. In many instances, we will be working in separate feature branches all on our own. In those cases, it's perfectly fine to rebase commits in that branch and push them up for review. I normally do this when I have very small units of work that need to be done, like with a few lines of code. If I have a larger unit of work, like say a new feature, I will tend to fixup locally but keep a history of the larger blocks of work being done. Keep in mind that this will require a force push, which will forcibly reset the remote branch to mirror your local branch.
If someone else is working on a branch with you, DO NOT REBASE AND FORCE PUSH to a remote branch. This will cause issues with other collaborators. Yes, it's all solvable, but it can cause a lot of issues as everyone tries to reconcile the force pushes.
Pulling In Parent Branch Changes
This situation is the one where most people run into issues. This workflow is when you have a feature branch that comes off your mainline code branch, which we will call main. main is getting updated constantly with other feature branches being merged in, and your feature branch needs to be updated to take advantage of those changes. You have two options. The first is to pull down and merge main into your feature branch. This will create a merge commit, and git will do its best to figure out how to merge the changes together.
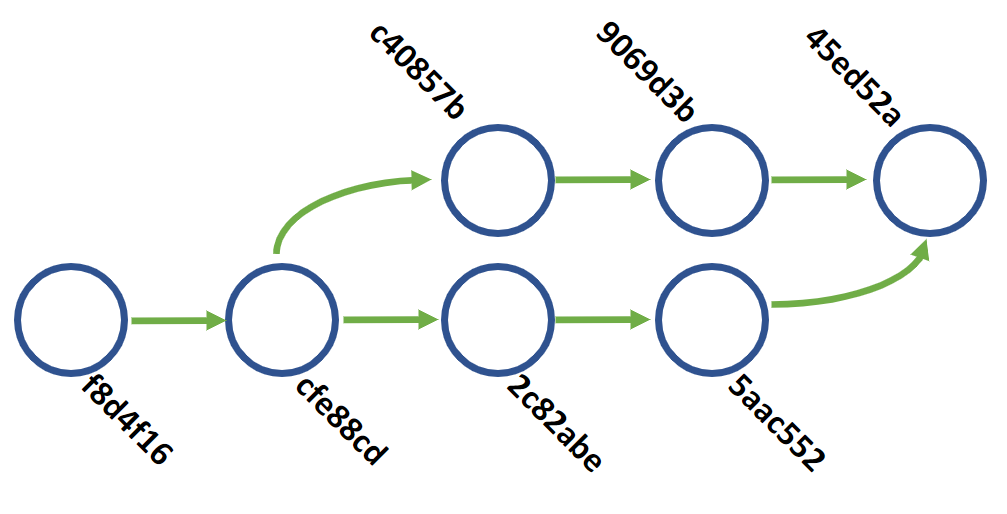
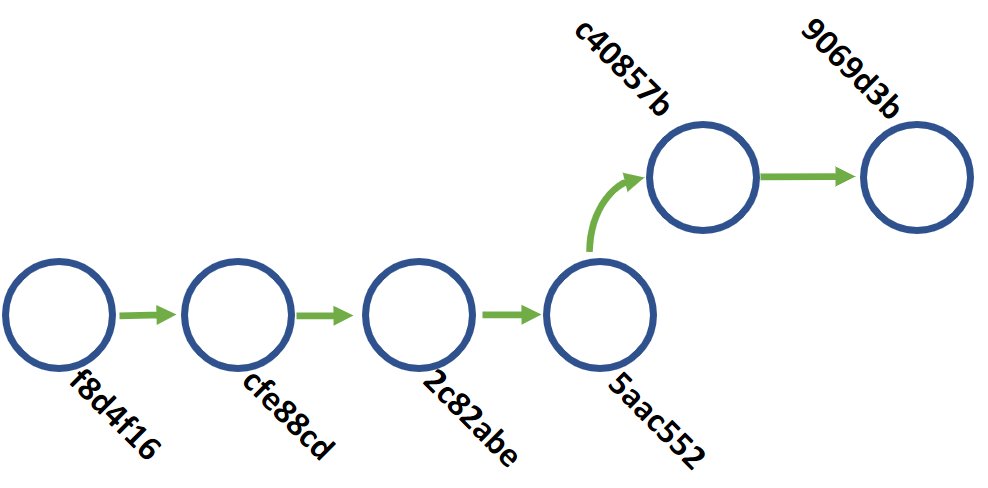
The second option is a rebase on main. As with our interactive rebase this will effectively move all of our feature branch commits to be after the current version of main and start our branch there. Our branch structure is a bit cleaner as we can better see that we depend on code from the 5aac552 commit rather than the cfe88cd commit we originally branched off of.
When is this safe?
It's always safe.
But Chris, this always causes conflicts!
Many times it does, but not because of the reason you think. The conflict occurs when git attempts to take your existing commit and reconcile it against the new files. If one of those files from main is a file you also edited, you may get a conflict. git tries its best to figure out how to merge changes but sometimes it cannot. This means you have to figure out how to reconcile it, or git rebase --abort and stop the rebase.
The larger issue at hand is that two developers changed the same blocks of code during two different feature sets. The solution is not to stop using rebase, but to better understand the scope of feature branches and make sure that work is not being done concurrently on the same portion of the codebase. This problem is exacerbated when a feature branch is very wide in scope or has a long lifetime as this widens the number of files that can be altered.
If you are constantly running into issues rebasing on a parent branch, first look at the work being scheduled. Make sure that the issues being worked on do not overlap in scope or code. Second, make sure that feature branches are short-lived. A branch that exists and is worked on for weeks or months at a time is grossly over-scoped. Break it into smaller feature branches or units of work in your planning. A good rule of thumb is that any issue that takes more than 8 person-hours is not broken up enough.
Your other option is to not use a rebase and just merge up from main. Rebasing is not an always or never situation.
"I'm worried about losing work"
Rebasing generally does not cause work to get lost, but resolving merge commits do. This is the biggest issue with most rebasing problems.
One of the most common mistakes is taking a feature branch and rebasing the parent. If there are a lot of differences as outlined above, you get a merge conflict. You now have to look at the code and figure out the best way to fix this, and there is this monster staring, urging you to finish the rebase as quickly as possible. You are stuck until you fix this.
You resolve the merge, and after-the-fact realize you lost a chunk of code, or you accidentally reverted the code to an earlier version. Now you are out of sync with main. You squashed something wrong and now the commit you needed is gone. What do you do?
The nice thing about git is that nothing is ever lost. If you need to find a commit, that is where the git reflog comes into play. The reflog is an activity log of what you have done with your local repository. You can use the reflog to find older commits and check them out, or reset them, or cherry-pick them back into the current timeline. It is not a complete history, however, and is designed to clean itself out every so often. The reflog is not a magical backup tool.
$ git reflog show
d4d525 (HEAD -> master) HEAD@{0}: rebase -i (finish): returning to refs/heads/master
ed4d525 (HEAD -> master) HEAD@{1}: rebase -i (pick): Updated dependencies
231fe64 HEAD@{2}: rebase -i (pick): Added The Contracts of Open Source
8eda557 HEAD@{3}: rebase -i (fixup): Added false promise article
5eec634 HEAD@{4}: rebase -i (fixup): # This is a combination of 3 commits.
083b44f HEAD@{5}: rebase -i (fixup): # This is a combination of 2 commits.
1ba90ea HEAD@{6}: rebase -i (start): checkout c23d576
b2b99fb HEAD@{7}: checkout: moving from 244426b03db6d06d62d4a6bedcb64c4baef3acb4 to master
244426b (origin/master, origin/HEAD) HEAD@{8}: pull --rebase origin master: checkout 244426b03db6d06d62d4a6bedcb64c4baef3acb4
Remember that earlier example where we ran a rebase and "fixup" 'd a few commits? This is what that rebase looks like in the reflog. I can git reset or git checkout any of the commits in the reflog. By default the reflog only shows the current branch, you can use git reflog show --all to set all the activity no matter the branch.
"Force pushing is scary"
Force pushing is scary because it can cause a lot of problems if other people do not realize you force pushed. Force pushing resets the timeline so that the remote branch matches your local one completely. The issue here is that if multiple people are also pulling down a branch from a central repository, a force push can quickly get them out of sync. This is most destructive when multiple people are committing to the same branch, and someone force pushes to that shared branch.
The good thing is the solution is easy! NEVER FORCE PUSH TO A SHARED BRANCH. Just do not do it.
If you must force push to a branch, then alert the other developers working on that branch. They will have two things they can do. The first is to fetch the new branch and git reset themselves to match. The reflog can be used to git cherry-pick their lost commits over.
The second is to do a git pull --rebase to try and automatically reconcile the branch. Depending on what caused the force push in the first place you may have merge conflicts, but hopefully, the reason and changes are clearly communicated by whoever did the force push.
Worst case you can always create temporary branches to play around in before you mess with your local branch.
"I hate all the merge conflicts and constant merges"
This goes back to one of my earlier notes: try and limit the scope of feature branches and make sure branches are short-lived. If you have lots of overlapping work between branches you are going to run into conflicts at some point anyway.
"I wish there was a way to see the outcome first"
The best way to do this is to create a temporary branch. Let's say we have a feature branch and we want to rebase on main, but see how that looks first.
// Assuming we are on our feature branch `feature/cool-feature`
$ git fetch origin main:main
$ git checkout -b dr-rebase-cool-feature
$ git rebase main
// See what happens and abort of fails
Since git allows you to create and throw away branches with ease, branching should be taken advantage of when possible.
Hopefully, this helps with showing when rebasing can be used, and what to do when things go wrong. Always remember you can git reset and use the reflog to pull back missing commits, and never force push to a shared branch!